Метод сопряженных градиентов в c. Метод сопряжённых градиентов
Градиентные методы, базирующиеся только на вычислении градиента R (x ), являются методами первого порядка, так как на интервале шага они заменяют нелинейную функцию R (x ) линейной.
Более эффективными могут быть методы второго порядка, которые используют при вычислении не только первые, но и вторые производные от R (x ) в текущей точке. Однако у этих методов есть свои труднорешаемые проблемы – вычисление вторых производных в точке, к тому же вдали от оптимума матрица вторых производных может быть плохо обусловлена.
Метод сопряженных градиентов является попыткой объединить достоинства методов первого и второго порядка с исключением их недостатков. На начальных этапах (вдали от оптимума) метод ведет себя как метод первого порядка, а в окрестностях оптимума приближается к методам второго порядка.
Первый шаг аналогичен первому шагу метода наискорейшего спуска, второй и следующий шаги выбираются каждый раз в направлении, образуемом в виде линейной комбинации векторов градиента в данной точке и предшествующего направления.
Алгоритм метода можно записать следующим образом (в векторной форме):
x 1 = x 0 – h grad R(x 0),
x i+1 = x i – h .
Величина α может быть приближенно найдена из выражения
Алгоритм работает следующим образом. Из начальной точки х 0 ищут minR (x ) в направлении градиента (методом наискорейшего спуска), затем, начиная с найденной точки и далее, направление поиска min определяется по второму выражению. Поиск минимума по направлению может осуществляться любым способом: можно использовать метод последовательного сканирования без коррекции шага сканирования при переходе минимума, поэтому точность достижения минимума по направлению зависит от величины шага h .
Для квадратичной функции R (x ) решение может быть найдено за п шагов (п – размерность задачи). Для других функций поиск будет медленнее, а в ряде случаев может вообще не достигнуть оптимума вследствие сильного влияния вычислительных ошибок.
Одна из возможных траекторий поиска минимума двумерной функции методом сопряженных градиентов приведена на рис. 1.
Алгоритм метода сопряжённых градиентов для поиска минимума.
Начальный этап. Выполнение градиентного метода.
Задаём начальное приближение x 1 0 , х 2 0 . Определяем значение критерия R (x 1 0 , х 2 0). Положить k = 0 и перейти к шагу 1 начального этапа.
Шаг
1.
 и
и

 .
.
Шаг
2.
Если модуль
градиента

Шаг 3.
x k+1 = x k – h grad R (x k)).
Шаг 4. R (x 1 k +1 , х 2 k +1). Если R (x 1 k +1 , х 2 k +1) < R (x 1 k , х 2 k), то положить k = k+1 и перейти к шагу 3. Если R (x 1 k +1 , х 2 k +1) ≥ R (x 1 k , х 2 k), то перейти к основному этапу.
Основной этап.
Шаг
1.
Вычислить
R(x 1 k
+
g,
x 2 k),
R(x 1 k
–
g,
x 2 k),
R(x 1 k ,
x 2 k
+
g),
R(x 1 k ,
x 2 k).
В соответствии с алгоритмом с центральной
или парной пробы вычислить значение
частных производных
 и
и
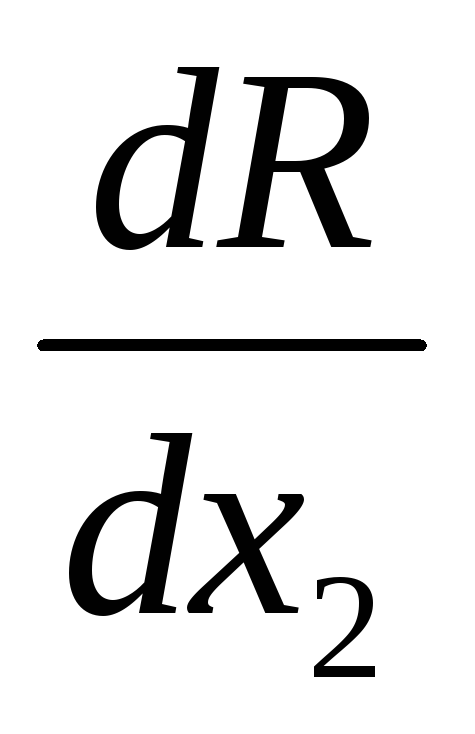 .
Вычислить значение модуля градиента
.
Вычислить значение модуля градиента
 .
.
Шаг
2.
Если модуль
градиента
 ,
то расчёт остановить, а точкой оптимума
считать точку (x 1 k ,
x 2 k).
В противном случае перейти к шагу 3.
,
то расчёт остановить, а точкой оптимума
считать точку (x 1 k ,
x 2 k).
В противном случае перейти к шагу 3.
Шаг 3. Вычислить коэффициент α в соответствии с формулой:

Шаг 4. Выполнить рабочий шаг, рассчитав по формуле
x k+1 = x k – h .
Шаг 5. Определить значение критерия R (x 1 k +1 , х 2 k +1). Положить k = k+1 и перейти к шагу 1.
Пример.
Для сравнения рассмотрим решение предыдущего примера. Первый шаг делаем по методу наискорейшего спуска (табл. 5).
Таблица 5
Найдена наилучшая точка. Вычисляем производные в этой точке: dR / dx 1 = –2.908; dR / dx 2 =1.600; вычисляем коэффициент α, учитывающий влияние градиента в предыдущей точке: α = 3,31920 ∙ 3,3192/8,3104 2 =0,160. Делаем рабочий шаг в соответствии с алгоритмом метода, получаем х 1 = 0,502, х 2 = 1,368. Далее все повторяется аналогично. Ниже, в табл. 6 приведены текущие координаты поиска следующих шагов.
Таблица 6
Вычислительные эксперименты для оценки эффективности параллельного варианта метода верхней релаксации проводились при условиях, указанных во введении. С целью формирования симметричной положительно определенной матрицы элементы подматрицы генерировались в диапа-зоне от 0 до 1, значения элементов подматрицы получались из симметрии матриц и , а элементы на главной диагонали (подматрица ) генерировались в диапазоне от до , где – размер матрицы.
В качестве критерия остановки использовался критерий остановки по точности (7.51) с параметром а итерационный параметр . Во всех экспериментах метод нашел решение с требуемой точностью за 11 итераций. Как и для предыдущих экспериментов, ускорение будем фиксировать по сравнению с параллельной программой, запущенной в один поток.
| n | 1 поток | Параллельный алгоритм | |||||||
| 2 потока | 4 потока | 6 потоков | 8 потоков | ||||||
| T | S | T | S | T | S | T | S | ||
| 2500 | 0,73 | 0,47 | 1,57 | 0,30 | 2,48 | 0,25 | 2,93 | 0,22 | 3,35 |
| 5000 | 3,25 | 2,11 | 1,54 | 1,22 | 2,67 | 0,98 | 3,30 | 0,80 | 4,08 |
| 7500 | 7,72 | 5,05 | 1,53 | 3,18 | 2,43 | 2,36 | 3,28 | 1,84 | 4,19 |
| 10000 | 14,60 | 9,77 | 1,50 | 5,94 | 2,46 | 4,52 | 3,23 | 3,56 | 4,10 |
| 12500 | 25,54 | 17,63 | 1,45 | 10,44 | 2,45 | 7,35 | 3,48 | 5,79 | 4,41 |
| 15000 | 38,64 | 26,36 | 1,47 | 15,32 | 2,52 | 10,84 | 3,56 | 8,50 | 4,54 |

Рис. 7.50.
Эксперименты демонстрируют неплохое ускорение (порядка 4 на 8-и потоках).
Метод сопряженных градиентов
Рассмотрим систему линейных уравнений (7.49) с симметричной, положительно определенной матрицей размера . Основой метода сопряженных градиентов является следующее свойство: решение системы линейных уравнений (7.49) с симметричной положительно определенной матрицей эквивалентно решению задачи минимизации функции
Обращается в ноль. Таким образом, решение системы (7.49) можно искать как решение задачи безусловной минимизации (7.56).
Последовательный алгоритм
С целью решения задачи минимизации (7.56) организуется следующий итерационный процесс.
Подготовительный шаг () определяется формулами
Где – произвольное начальное приближение; а коэффициент вычисляется как

) определяются формулами
Здесь – невязка -го приближения, коэффициент находят из условия сопряженности
![]()
Направлений и ; является решением задачи минимизации функции по направлению
Анализ расчетных формул метода показывает, что они включают две операции умножения матрицы на вектор, четыре операции скалярного произведения и пять операций над векторами. Однако на каждой итерации произведение достаточно вычислить один раз, а затем использовать сохраненный результат. Общее количество числа операций, выполняемых на одной итерации, составляет
![]()
Таким образом, выполнение итераций метода потребует
| (7.58) |
Операций. Можно показать, что для нахождения точного решения системы линейных уравнений с положительно определенной симметричной матрицей необходимо выполнить не более n итераций, тем самым, сложность алгоритма поиска точного решения имеет порядок . Однако ввиду ошибок округления данный процесс обычно рассматривают как итераци- онный, процесс завершается либо при выполнении обычного условия остановки (7.51) , либо при выполнении условия малости относительной нормы невязки
![]()
Организация параллельных вычислений
При разработке параллельного варианта метода сопряженных градиентов для решения систем линейных уравнений в первую очередь следует учесть, что выполнение итераций метода осуществляется последовательно и, тем самым, наиболее целесообразный подход состоит в распараллеливании вычислений, реализуемых в ходе выполнения итераций.
Анализ последовательного алгоритма показывает, что основные затраты на -й итерации состоят в умножении матрицы на вектора и . Как ре- зультат, при организации параллельных вычислений могут быть использованы известные методы параллельного умножения матрицы на вектор.
Дополнительные вычисления, имеющие меньший порядок сложности, представляют собой различные операции обработки векторов (скалярное произведение, сложение и вычитание, умножение на скаляр). Организация таких вычислений, конечно же, должна быть согласована с выбранным параллельным способом выполнения операция умножения матрицы на вектор.
Выберем для дальнейшего анализа эффективности получаемых параллельных вычислений параллельный алгоритм матрично-векторного умножения при ленточном горизонтальном разделении матрицы. При этом операции над векторами, обладающие меньшей вычислительной трудоемкостью, также будем выполнять в многопоточном режиме.
Вычислительная трудоемкость последовательного метода сопряженных градиентов определяется соотношением (7.58). Определим время выполнения параллельной реализации метода сопряженных градиентов. Вычислительная сложность параллельной операции умножения матрицы на вектор при использовании схемы ленточного горизонтального разделения матрицы составляет
Где – длина вектора, – число потоков, – накладные расходы на созда- ние и закрытие параллельной секции.
Все остальные операции над векторами (скалярное произведение, сложение, умножение на константу) могут быть выполнены в однопоточном режиме, т.к. не являются определяющими в общей трудоемкости метода. Следовательно, общая вычислительная сложность параллельного варианта метода сопряженных градиентов может быть оценена как

Где – число итераций метода.
Результаты вычислительных экспериментов
Вычислительные эксперименты для оценки эффективности параллельного варианта метода сопряженных градиентов для решения систем линейных уравнений с симметричной положительно определенной матрицей прово- дились при условиях, указанных во введении. Элементы на главной диагонали матрицы ) генерировались в диапазоне от до , где – размер матрицы, остальные элементы генерировались симметрично в диапазоне от 0 до 1. В качестве критерия остановки использовался критерий остановки по точности (7.51) с параметром
Результаты вычислительных экспериментов приведены в таблице 7.21 (время работы алгоритмов указано в секундах).
Метод наискорейшего спуска
При использовании метода наискорейшего спуска на каждой итерации величина шага а
k
выбирается из условия минимума функции f(x)
в направлении спуска, т. е.
f(x
[k
] -a
k
f"(x
[k
]))
= f(x
[k] - af"(x
[k
]))
.
Это условие означает, что движение вдоль антиградиента происходит до тех пор, пока значение функции f(x)
убывает. С математической точки зрения на каждой итерации необходимо решать задачу одномерной минимизации по а
функции
j(a)
= f(x
[k
] - af"(x
[k
])) .
Алгоритм метода наискорейшего спуска состоит в следующем.
1. Задаются координаты начальной точки х .
2. В точке х [k ], k = 0, 1, 2, ... вычисляется значение градиента f"(x [k ]) .
3. Определяется величина шага a k , путем одномерной минимизации по а функции j(a) = f(x [k ] - af"(x [k ])).
4. Определяются координаты точки х [k+ 1]:
х i [k+ 1] = x i [k ] - а k f" i (х [k ]), i = 1 ,..., п.
5. Проверяются условия останова стерационного процесса. Если они выполняются, то вычисления прекращаются. В противном случае осуществляется переход к п. 1.
В рассматриваемом методе направление движения из точки х [k ] касается линии уровня в точке x [k+ 1] (Рис. 2.9). Траектория спуска зигзагообразная, причем соседние звенья зигзага ортогональны друг другу. Действительно, шаг a k выбирается путем минимизации по а функции ц(a) = f(x [k] - af"(x [k ])) . Необходимое условие минимума функции d j(a)/da = 0. Вычислив производную сложной функции, получим условие ортогональности векторов направлений спуска в соседних точках:
d j(a)/da = -f"(x [k+ 1]f"(x [k ]) = 0.
Градиентные методы сходятся к минимуму с высокой скоростью (со скоростью геометрической прогрессии) для гладких выпуклых функций. У таких функций наибольшее М и наименьшее m собственные значения матрицы вторых производных (матрицы Гессе)

мало отличаются друг от друга, т. е. матрица Н(х) хорошо обусловлена. Напомним, что собственными значениями l i , i =1, …, n , матрицы являются корни характеристического уравнения

Однако на практике, как правило, минимизируемые функции имеют плохо обусловленные матрицы вторых производных (т/М << 1). Значения таких функций вдоль некоторых направлений изменяются гораздо быстрее (иногда на несколько порядков), чем в других направлениях. Их поверхности уровня в простейшем случае сильно вытягиваются, а в более сложных случаях изгибаются и представляют собой овраги. Функции, обладающие такими свойствами, называют овражными. Направление антиградиента этих функций (см. Рис. 2.10) существенно отклоняется от направления в точку минимума, что приводит к замедлению скорости сходимости.
Метод сопряженных градиентов
Рассмотренные выше градиентные методы отыскивают точку минимума функции в общем случае лишь за бесконечное число итераций. Метод сопряженных градиентов формирует направления поиска, в большей мере соответствующие геометрии минимизируемой функции. Это существенно увеличивает скорость их сходимости и позволяет, например, минимизировать квадратичную функцию
f(x) = (х, Нх) + (b, х) + а
с симметрической положительно определенной матрицей Н за конечное число шагов п, равное числу переменных функции. Любая гладкая функция в окрестности точки минимума хорошо аппроксимируется квадратичной, поэтому методы сопряженных градиентов успешно применяют для минимизации и неквадратичных функций. В таком случае они перестают быть конечными и становятся итеративными.
По определению, два n -мерных вектора х и у называют сопряженными по отношению к матрице H (или H -сопряженными), если скалярное произведение (x , Ну) = 0. Здесь Н - симметрическая положительно определенная матрица размером п хп.
Одной из наиболее существенных проблем в методах сопряженных градиентов является проблема эффективного построения направлений. Метод Флетчера-Ривса решает эту проблему путем преобразования на каждом шаге антиградиента -f(x [k ]) в направление p [k ], H -сопряженное с ранее найденными направлениями р , р , ..., р [k -1]. Рассмотрим сначала этот метод применительно к задаче минимизации квадратичной функции.
Направления р [k ] вычисляют по формулам:
p [k ] = -f"(x [k ]) +b k-1 p [k -l], k >= 1;
p = -f "(x ) .
Величины b k -1 выбираются так, чтобы направления p [k ], р [k -1] были H -сопряженными:
(p [k ], Hp [k- 1])= 0.
В результате для квадратичной функции
итерационный процесс минимизации имеет вид
x [k +l] =x [k ] +a k p [k ],
где р [k ] - направление спуска на k- м шаге; а k - величина шага. Последняя выбирается из условия минимума функции f(х) по а в направлении движения, т. е. в результате решения задачи одномерной минимизации:
f(х [k ] + а k р [k ]) = f(x [k ] + ар [k ]) .
Для квадратичной функции
Алгоритм метода сопряженных градиентов Флетчера-Ривса состоит в следующем.
1. В точке х вычисляется p = -f"(x ) .
2. На k- м шаге по приведенным выше формулам определяются шаг а k . и точка х [k+ 1].
3. Вычисляются величины f(x [k +1]) и f"(x [k +1]) .
4. Если f"(x ) = 0, то точка х [k +1] является точкой минимума функции f(х). В противном случае определяется новое направление p [k +l] из соотношения
и осуществляется переход к следующей итерации. Эта процедура найдет минимум квадратичной функции не более чем за п шагов. При минимизации неквадратичных функций метод Флетчера-Ривса из конечного становится итеративным. В таком случае после (п+ 1)-й итерации процедуры 1-4 циклически повторяются с заменой х на х [п +1] , а вычисления заканчиваются при, где - заданное число. При этом применяют следующую модификацию метода:
x [k +l] = x [k ] +a k p [k ],
p [k ] = -f"(x [k ])+ b k- 1 p [k -l], k >= 1;
p = -f"(x );
f(х [k ] + a k p [k ]) = f(x [k ] + ap [k ];

Здесь I - множество индексов: I = {0, n, 2п, Зп, ...} , т. е. обновление метода происходит через каждые п шагов.
Геометрический смысл метода сопряженных градиентов состоит в следующем (Рис. 2.11). Из заданной начальной точки х осуществляется спуск в направлении р = -f"(x ). В точке х определяется вектор-градиент f"(x ). Поскольку х является точкой минимума функции в направлении р , то f"(х ) ортогонален вектору р . Затем отыскивается вектор р , H -сопряженный к р . Далее отыскивается минимум функции вдоль направления р и т. д.

Рис. 2.11.
Методы сопряженных направлений являются одними из наиболее эффективных для решения задач минимизации. Однако следует отметить, что они чувствительны к ошибкам, возникающим в процессе счета. При большом числе переменных погрешность может настолько возрасти, что процесс придется повторять даже для квадратичной функции, т. е. процесс для нее не всегда укладывается в п шагов.
Термин "метод сопряженных градиентов" – один из примеров того, как бессмысленные словосочетания, став привычными, воспринимаются сами собой разумеющимися и не вызывают никакого недоумения. Дело в том, что, за исключением частного и не представляющего практического интереса случая, градиенты не являются сопряженными, а сопряженные направления не имеют ничего общего с градиентами. Название метода отражает тот факт, что данный метод отыскания безусловного экстремума сочетает в себе понятия градиента целевой функции и сопряженных направлений.
Несколько слов об обозначениях, используемых далее.
Скалярное произведение двух векторов записывается $x^Ty$ и представляет сумму скаляров: $\sum_{i=1}^n\, x_i\,y_i$. Заметим, что $x^Ty = y^Tx$. Если x и y ортогональны, то $x^Ty = 0$. В общем, выражения, которые преобразуются к матрице 1х1, такие как $x^Ty$ и $x^TA_x$, рассматриваются как скалярные величины.
Первоначально метод сопряженных градиентов был разработан для решения систем линейных алгебраических уравнений вида:
где x – неизвестный вектор, b – известный вектор, а A – известная, квадратная, симметричная, положительно–определенная матрица. Решение этой системы эквивалентно нахождению минимума соответствующей квадратичной формы.
Квадратичная форма – это просто скаляр, квадратичная функция некого вектора x следующего вида:
$f\,(x) = (\frac{1}{2})\,x^TA_x\,-\,b^Tx\,+\,c$, (2)
Наличие такой связи между матрицей линейного преобразования A и скалярной функцией f(x) дает возможность проиллюстрировать некоторые формулы линейной алгебры интуитивно понятными рисунками. Например, матрица А называется положительно-определенной, если для любого ненулевого вектора x справедливо следующее:
$x^TA_x\,>\,0$, (3)
На рисунке 1 изображено как выглядят квадратичные формы соответственно для положительно-определенной матрицы (а), отрицательно-определенной матрицы (b), положительно-неопределенной матрицы (с), неопределенной матрицы (d).
То есть, если матрица А – положительно-определенная, то вместо того, чтобы решать систему уравнений 1, можно найти минимум ее квадратичной функции. Причем, метод сопряженных градиентов сделает это за n или менее шагов, где n – размерность неизвестного вектора x. Так как любая гладкая функция в окрестностях точки своего минимума хорошо аппроксимируется квадратичной, этот же метод можно применить для минимизации и неквадратичных функций. При этом метод перестает быть конечным, а становится итеративным.
Рассмотрение метода сопряженных градиентов целесообразно начать с рассмотрения более простого метода поиска экстремума функции – метода наискорейшего спуска. На рисунке 2 изображена траектория движения в точку минимума методом наискорейшего спуска. Суть этого метода:
- в начальной точке x(0) вычисляется градиент, и движение осуществляется в направлении антиградиента до тех пор, пока уменьшается целевая функция;
- в точке, где функция перестает уменьшаться, опять вычисляется градиент, и спуск продолжается в новом направлении;
- процесс повторяется до достижения точки минимума.

В данном случае каждое новое направление движения ортогонально предыдущему. Не существует ли более разумного способа выбора нового направления движения? Существует, и он называется метод сопряженных направлений. А метод сопряженных градиентов как раз относится к группе методов сопряженных направлений. На рисунке 3 изображена траектория движения в точку минимума при использовании метода сопряженных градиентов.

Определение сопряженности формулируется следующим образом: два вектора x и y называют А-сопряженными (или сопряженными по отношению к матрице А) или А–ортогональными, если скалярное произведение x и Ay равно нулю, то есть:
$x^TA_y\,=\,0$, (4)
Сопряженность можно считать обобщением понятия ортогональности. Действительно, когда матрица А – единичная матрица, в соответствии с равенством 4, векторы x и y – ортогональны. Можно и иначе продемонстрировать взаимосвязь понятий ортогональности и сопряженности: мысленно растяните рисунок 3 таким образом, чтобы линии равного уровня из эллипсов превратились в окружности, при этом сопряженные направления станут просто ортогональными.
Остается выяснить, каким образом вычислять сопряженные направления. Один из возможных способов – использовать методы линейной алгебры, в частности, процесс ортогонализации Грамма–Шмидта. Но для этого необходимо знать матрицу А, поэтому для большинства задач (например, обучение многослойных нейросетей) этот метод не годится. К счастью, существуют другие, итеративные способы вычисления сопряженного направления, самый известный – формула Флетчера-Ривса:
$d_{(i+1)} = d_{(i+1)}\,+\,\beta_{(i+1)}\,d_i$ , (5)
$\beta_{(i+1)} = \frac{r_{(i+1)}^T}{r_{i}^T}\,\frac{r_{(i+1)}}{r_{(i)}}$, (6)
Формула 5 означает, что новое сопряженное направление получается сложением антиградиента в точке поворота и предыдущего направления движения, умноженного на коэффициент, вычисленный по формуле 6. Направления, вычисленные по формуле 5, оказываются сопряженными, если минимизируемая функция задана в форме 2. То есть для квадратичных функций метод сопряженных градиентов находит минимум за n шагов (n – размерность пространства поиска). Для функций общего вида алгоритм перестает быть конечным и становится итеративным. При этом, Флетчер и Ривс предлагают возобновлять алгоритмическую процедуру через каждые n + 1 шагов.
Можно привести еще одну формулу для определения сопряженного направления, формула Полака–Райбера (Polak-Ribiere):
$\beta_{(i+1)} = \frac{r_{(i+1)}^T\,(r_{(i+1)}\,-\,r_{(i)})}{r_{i}^T\,r_{(i)}}$, (7)
Метод Флетчера-Ривса сходится, если начальная точка достаточно близка к требуемому минимуму, тогда как метод Полака-Райбера может в редких случаях бесконечно циклиться. Однако последний часто сходится быстрее первого метода. К счастью, сходимость метода Полака-Райбера может быть гарантирована выбором $\beta = \max \{\beta;\,0\}$. Это эквивалентно рестарту алгорима по условию $\beta \leq 0$. Рестарт алгоритмической процедуры необходим, чтобы забыть последнее направление поиска и стартовать алгоритм заново в направлении скорейшего спуска.
- Вычисляется антиградиент в произвольной точке x (0) .
$d_{(0)} = r_{(0)} = -\,f"(x_{(0)})$
- Осуществляется спуск в вычисленном направлении пока функция уменьшается, иными словами, поиск a (i) , который минимизирует
$f\,(x_{(i)}\,+\,a_{(i)}\,d_{(i)})$
- Переход в точку, найденную в предыдущем пункте
$x_{(i+1)} = x_{(i)}\,+\,a_{(i)}\,d_{(i)}$
- Вычисление антиградиента в этой точке
$r_{(i+1)} = -\,f"(x_{(i+1)})$
- Вычисления по формуле 6 или 7. Чтобы осуществить рестарт алгоритма, то есть забыть последнее направление поиска и стартовать алгоритм заново в направлении скорейшего спуска, для формулы Флетчера–Ривса присваивается 0 через каждые n + 1 шагов, для формулы Полака-Райбера – $\beta_{(i+1)} = \max \{\beta_{(i+1)},\,0\}$
- Вычисление нового сопряженного направления
$d_{(i+1)} = r_{(i+1)}\,+\,\beta_{(i+1)}\,d_{(i)}$
- Переход на пункт 2.
Из приведенного алгоритма следует, что на шаге 2 осуществляется одномерная минимизация функции. Для этого, в частности, можно воспользоваться методом Фибоначчи, методом золотого сечения или методом бисекций. Более быструю сходимость обеспечивает метод Ньютона–Рафсона, но для этого необходимо иметь возможность вычисления матрицы Гессе. В последнем случае, переменная, по которой осуществляется оптимизация, вычисляется на каждом шаге итерации по формуле:
$$a = -\,\frac{{f"}^T\,(x)\,d}{d^T\,f""(x)\,d}$$
$f""(x)\,= \begin{pmatrix} \frac{\partial^2\,f}{\partial x_1\,\partial x_1}&\frac{\partial^2\,f}{\partial x_1\,\partial x_2}&\cdots&\frac{\partial^2\,f}{\partial x_1\,\partial x_n}& \\ \frac{\partial^2\,f}{\partial x_2\,\partial x_1}&\frac{\partial^2\,f}{\partial x_2\,\partial x_2}& \cdots&\frac{\partial^2\,f}{\partial x_2\,\partial x_n}& \\ \vdots&\vdots&\ddots&\vdots &\\ \frac{\partial^2\,f}{\partial x_n\,\partial x_1}& \frac{\partial^2\,f}{\partial x_n\,\partial x_2}&\cdots&\frac{\partial^2\,f}{\partial x_n\,\partial x_n} \end{pmatrix}$
Матрица Гессе
Несколько слов об использовании метода сопряженных направлений при обучении нейронных сетей. В этом случае используется обучение по эпохам, то есть при вычислении целевой функции предъявляются все шаблоны обучающего множества и вычисляется средний квадрат функции ошибки (или некая ее модификация). То же самое – при вычислении градиента, то есть используется суммарный градиент по всему обучающему набору. Градиент для каждого примера вычисляется с использованием алгоритма обратного распространения (BackProp).
В заключение приведем один из возможных алгоритмов программной реализации метода сопряженных градиентов. Сопряженность в данном случае вычисляется по формуле Флетчера–Ривса, а для одномерной оптимизации используется один из вышеперечисленных методов. По мнению некоторых авторитетных специалистов скорость сходимости алгоритма мало зависит от оптимизационной формулы, применяемой на шаге 2 приведенного выше алгоритма, поэтому можно рекомендовать, например, метод золотого сечения, который не требует вычисления производных.
Вариант метода сопряженных направлений, использующий формулу Флетчера-Ривса для расчета сопряженных направлений.
r:= -f"(x) // антиградиент целевой функции
d:= r // начальное направление спуска совпадает с антиградиентом
Sigma new: = r T * r // квадрат модуля антиградиента
Sigma 0: = Sigma new
// Цикл поиска (выход по счетчику или ошибке)
while i < i max and Sigma new > Eps 2 * Sigma 0
begin
j: = 0
Sigma d: = d T * d
// Цикл одномерной минимизации (спуск по направлению d)
repeat
a: =
x: = x + a
j: = j + 1
until (j >= j max) or (a 2 * Sigma d <= Eps 2)
R: = -f"(x) // антиградиент целевой функции в новой точке
Sigma old: = Sigma new
Sigma new: = r T * r
beta: = Sigma new / Sigma old
d: = r + beta * d // Вычисление сопряженного направления
k: = k + 1
If (k = n) or (r T * d <= 0) then // Рестарт алгоритма
begin
d: = r
k: = 0
end
I: = i + 1
end
Метод сопряженных градиентов является методом первого порядка, в то же время скорость его сходимости квадратична. Этим он выгодно отличается от обычных градиентных методов. Например, метод наискорейшего спуска и метод координатного спуска для квадратичной функции сходятся лишь в пределе, в то время как метод сопряженных градиентов оптимизирует квадратичную функцию за конечное число итераций. При оптимизации функций общего вида, метод сопряженных направлений сходится в 4-5 раз быстрее метода наискорейшего спуска. При этом, в отличие от методов второго порядка, не требуется трудоемких вычислений вторых частных производных.
Литература
- Н.Н.Моисеев, Ю.П.Иванилов, Е.М.Столярова "Методы оптимизации", М. Наука, 1978
- А.Фиакко, Г.Мак-Кормик "Нелинейное программирование", М. Мир, 1972
- У.И.Зангвилл "Нелинейное программирование", М. Советское радио, 1973
- Jonathan Richard Shewchuk "Second order gradients methods", School of Computer Science Carnegie Mellon University Pittsburg, 1994
Метод сопряженных градиентов для нахождения максимума квадратичной формы имеет несколько модификаций.
1. Одна из них получается непосредственно из рассмотренного выше процесса, если заменить максимизацию функции на гиперпространстве отысканием максимума на прямой вида (16.15). Как было показано в предыдущем пункте результат от этого не изменится, так как эти максимумы совпадают.
Алгоритм получается таким (модификация I):
А. Начальный шаг.
1) Находится градиент функции в произвольной точке ;
2) полагается ;
3) находится точка , доставляющая максимум функции на прямой ( – параметр).
Б. Общий шаг. Пусть уже найдены
точки ![]() .
.
1) находится градиент функции в точке .
2) полагается
В. Останов алгоритма. Процесс обрывается в тот момент, когда градиент обратится в нуль, т. е. достигается максимум на всем пространстве .
При абсолютно точном вычислении алгоритм должен привести к максимуму не более чем за шагов, так как при этом точки вычисляемые методом сопряженных градиентов, совпадают с точками , получающимися в процессе, описанном в предыдущем пункте: как было показано, этот процесс выводит на абсолютный максимум не более чем за шагов.
В реальных условиях, при ограниченной точности вычислений, процесс поиска максимума следует остановить не при точном обращении в нуль градиента, а в тот момент, когда градиент станет достаточно мал. При этом на самом деле может потребоваться более шагов. Более подробно эти вопросы будут рассмотрены ниже.
Чтобы придать алгоритму более «конструктивную» форму, найдем формулу, определяющую точку максимума квадратичной формы на прямой .
Подставляя уравнение прямой в выражение функции , получим
где – градиент в точке . Максимизируя по , получим

и соответственно
 . (16.16)
. (16.16)
Таким образом, вычисление в пункте 3) алгоритма может быть осуществлено по формуле
 .
.
2. Более известна модификация метода, при которой для вычисления очередного направления используются векторы и вместо и .
Рассмотрим систему векторов , коллинеарных соответственно векторам (т. е. при некоторых действительных ). Для векторов и сохраняется условие -ортогональности
При . (16.17)
Кроме того, из (16.11) следует, что
При . (16.18)
Наконец, остается в силе соотношение типа (16.9)
 . (16.19)
. (16.19)
Умножая правую и левую части (16.19) на и учитывая (16.17) и (16.18), получим при
откуда при . При получим
 . (16.20)
. (16.20)
Соотношение (16.20) определяет с точностью до произвольного множителя через и ц. При выводе (16.20) использовались лишь соотношения (16.17), (16.18), (16.19). Поэтому процесс построения векторов может рассматриваться как процесс -ортогонализации векторов .
Полагая в (16.20) и , получим конкретную систему векторов , коллинеарных . Каждый вектор задает направление прямой, исходящей из , на которой лежит . Алгоритм, таким образом, примет следующий вид (модификация II).
А. Начальный шаг, такой же как и в модификации I.
Б. Пусть уже найдены точка и направление .
1) Находится градиент функции в точке ;
2) полагается
![]() ,
,
 ; (16.21)
; (16.21)
3) находится точка , доставляющая условный максимум на прямой
по формуле
 . (16.22)
. (16.22)
Формулы (16.21) и (16.22) могут быть преобразованы. Так, полагая
имеем из (16.22)
![]() ,
,
откуда получаем, применяя (16.12),
 . (16.23)
. (16.23)
С другой стороны, поскольку
из (16.21) имеем
и, таким образом,
Наконец, из (16.21), (16.23) и (16.24) получаем
 .
.
Таким образом, формулы (16.21) и (16.22) могут быть записаны в виде
![]() ,
,
 . (16.26)
. (16.26)
Совпадение результатов действия по формулам (16.21) и (16.22), с одной стороны, и (16.25), (16.26), с другой, может служить критерием правильности вычислений.
3. Метод сопряженных градиентов может быть применен и для максимизации функций , не являющихся квадратичными. Известно, однако, что вблизи максимума достаточно гладкие функции, как правило, хорошо аппроксимируются квадратичной функцией, например, с помощью разложения в ряд Тейлора. При этом обычно предполагается, что коэффициенты аппроксимирующей квадратичной функции неизвестны, но для любой точки можно найти градиент функции .
При этом пункт 1) алгоритма может быть выполнен без изменений, пункт 2) должен выполняться по формуле (16.25), поскольку в эту формулу не входит явно матрица , а пункт 3), нахождение условного максимума на прямой, может быть выполнен одним из известных способов, например, методом Фибоначчи. Применение метода сопряженных градиентов дает обычно значительно более быструю сходимость к максимуму по сравнению с методами наискорейшего спуска, Гаусса – Зайделя и др.
4. Что будет, если применить метод сопряженных градиентов для максимизации квадратичной формы с положительно полуопределенной формой ?
Если квадратичная форма положительно полуопределена, то, как известно из линейной алгебры, в соответствующей системе координат функция примет вид
 ,
,
где все и некоторые из . При этом функция имеет максимум, если выполнено условие: когда , то и . Легко видеть, что максимум в этом случае достигается на целом гиперпространстве. А именно, пусть, например, при , меняющемся от 1 до , , а при , меняющемся от до , и . Тогда максимум достигается в точках с координатами при и с произвольными значениями при . Они образуют гиперпространство размерности .
Если же при некоторых , a , то функция не имеет максимума и возрастает неограниченно. В самом деле, пусть, например, и ; тогда, если положить при и устремить к , то, очевидно, и будет возрастать до бесконечности.
Оказывается, что метод сопряженных градиентов (при точном счете) позволяет в первом случае достигнуть максимума не более чем за шагов, где – число не равных нулю, а во втором случае не более чем через шагов выводит на направление, по которому функция возрастает неограниченно.
В исходной системе координат функция имеет вид
![]() ,
,
причем матрица вырождена и имеет ранг . При этом, как и раньше, обращение градиента в нуль есть критерий достижения максимума, а ортогональность градиента гиперпространству – критерий условного экстремума на гиперпространстве.
Рассмотрим применение метода сопряженных градиентов в форме II в этом случае. Здесь приходится изменить условие остановки, т. е. теперь возможно, что при вычислении длины шага

знаменатель может обратиться в нуль (при вычислении значения величина также входит в знаменатель, но если она равна нулю, то уже предыдущий шаг невозможен).. В самом деле пусть при ортогонален гиперпространству
и так как , то квадратичная часть положительно определена. Но, как известно из линейной алгебры, это возможно только в том случае, когда размерность пространства меньше или равна рангу матрицы .
Следовательно, останов обязательно произойдет при .